
分類問題を解く方法、ロジスティック回帰を使ってみよう|Pythonで機械学習vol.3
- Python
- 機械学習
notari株式会社


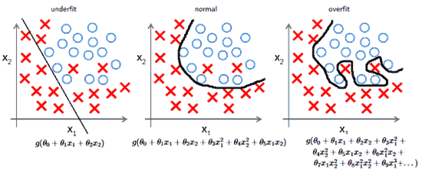
http://mlwiki.org/index.php/Overfitting日本語では「過学習」や「過剰適合」と呼ばれており、訓練データに対して学習されているが、テストデータに対しては適合できていない、汎化できていない状態を指します。機械学習では通常、学習アルゴリズムは一連の訓練データを使って訓練され、訓練データでは示されなかった他の例についても正しい出力を返すことができるようになると期待されます。上の図(○と×を分類している)は、前回の記事で扱ったロジスティック回帰の例で、左から順に、アンダーフィッティング、正常、オーバーフィッティングとなっています。アンダーフィッティングの場合、モデルがシンプルすぎて×のデータを拾いきれておらず、精度(正答率)が低い状態を示しています。逆にオーバーフィッティングの場合、精度は100%なのですがモデルが複雑になりすぎており、未知のデータが入力された際の誤回答率があがってしまいます。そのため、シンプルすぎず複雑すぎず、稀にあるノイズに反応しにくいモデルが理想とされています。オーバーフィッティングの原因として、特徴量が大きいときや高次の特徴があるとき、または訓練データ数が少ないといったことが考えられます。
https://en.wikipedia.org/wiki/Regularization_(mathematics)
オーバーフィッティングを避ける方法として特徴量を減らす、もしくは正則化が考えられます。正則化とは、モデルの複雑さに罰則を科すために導入され、なめらかでない事に罰則をかけたり、パラメータのノルムの大きさに罰則をかけたりすることです。
解析学において、ノルムは、平面あるいは空間における幾何学的ベクトルの “長さ” の概念の一般化であり、ベクトル空間に対して「距離」を与えるための数学の道具である。ノルムの定義されたベクトル空間を線型ノルム空間または単にノルム空間という。
では、実際にこれまで使ってきたScikit learnのロジスティック回帰を用いて説明していきます。
まずはいつも通りMacの場合はターミナル、Windowsの場合はコマンドプロンプトから任意のディレクトリに移動し、Jupyterを起動します。
$ jupyter notebook
起動したら新規ファイルを作成して編集画面を表示しましょう。
そして、いつも通り今回利用するライブラリーやモジュールを下のコマンドでインポートします。
(今回もサンプルで癌データを用います)
# 分析用
import numpy as np
# プロット用
import matplotlib.pyplot as plt
%matplotlib inline
# 機械学習用
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import ShuffleSplit
# がんデータ
from sklearn.datasets import load_breast_cancer
# スケーリング用
from sklearn.preprocessing import MinMaxScaler
次に、サンプルデータを読み込み変数にデータを格納します。
cancer = load_breast_cancer()
X = cancer.data
y = cancer.target
前回同様、Cross Validationを行うためにShuffleSplitを使って、元データから訓練データとテストデータをランダムに選択します。
ss = ShuffleSplit(n_splits=1,
train_size=0.8,
test_size=0.2,
random_state=0)
train_index, test_index = next(ss.split(X, y))
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
更に、データのスケーリングを行い対象の変数に格納します。
特徴量のとりうる値の範囲をあらかじめ調整してあげることです。
スケーリングをする理由は2つあります。
大きい値の範囲をとる特徴量に引きずられないようにします。[0,10]での1と2の違いは1だけですが、[0,10000]での1の100の違いよりもずっと重要です。すなわち、これらを対等に比較するために、それぞれの特徴量を同じ範囲にスケールしてあげる必要があります。
カーネル関数は特徴ベクトルの内積を用いて計算するので、スケーリングを行わずに計算すると,大きい値×小さい値となり,情報落ちする可能性があります。
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
これで事前準備は完了です。
ロジスティック回帰のインスタンスを用意し、fit()メソッドを呼んでモデルを生成すると共に、訓練データの精度(正答率)を表示します。
clf = LogisticRegression()
clf.fit(X_train, y_train)
clf.score(X_test, y_test)

ここまでは前回同様、デフォルトで用意されているロジスティック回帰を使ってがんの発症予測を分類しただけです。今回は正則化パラメータであるCの値を調整していきます。
デフォルトでは、正則化の程度を調整できるパラメータC = 1で格納されています。
clf

これをC = 100に変更して、モデルを再生成して先程と同様に訓練データの精度を表示します。
するとC = 1の場合よりも、モデルの精度が増加しているのがわかるかと思います。
しかし、前半で説明したとおり、このパラメータが大きすぎると過学習となってしまうため、丁度よいCの値を探る必要があります。
そこで、計算時間を計測しながらループ処理を用いて探っていきます。
今回は時間を扱う関数を備えているtimeモジュールをインポートします。
import time
ではCの値を10の-20乗(1垓分の1)から15乗(1000兆)の範囲まで、乗数をひと段階あげながら各乗数でのモデル精度と計算処理にかかった時間をみていきましょう。
C_range_exp = np.arange(-20., 15.)
C_range = 10 ** C_range_exp
scores = []
comp_time = []
for C in C_range:
clf.C = C
st = time.time()
clf.fit(X_train, y_train)
comp_time.append(time.time() - st)
score = clf.score(X_test, y_test)
print(C, score)
scores.append(score)
scores = np.array(scores)
comp_time = np.array(comp_time)

左側に乗数、右側に精度が表示されているのを確認してください。
より見やすくするためにY軸を精度、X軸を乗数として処理結果をプロットしてみます。
plt.plot(C_range_exp, scores)
plt.ylabel("accuracy")
plt.xlabel(r"$\log_{10}$(C)");
plt.show()
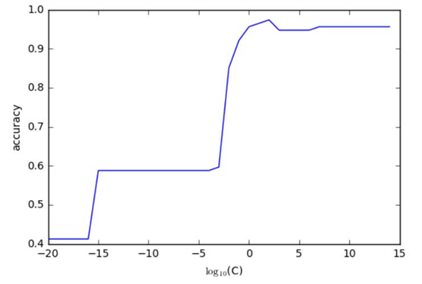
この図から、乗数が2(C = 100)のときにもっともモデルの精度が高いことがわかります。
次にY軸を計算処理時間、X軸を乗数として処理結果をプロットしてみましょう。
plt.plot(C_range_exp, comp_time)
plt.ylabel("computation time [sec]")
plt.xlabel(r"$\log_{10}$(C)");
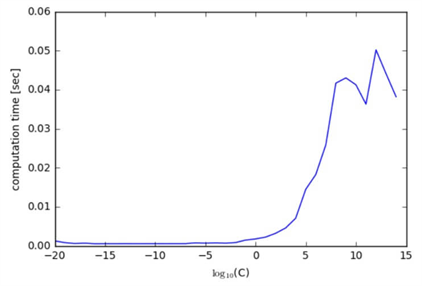
この図からは大まかにCの値が大きければ大きいほど、計算処理に時間がかかっていることがわかります。これらの結果をもとに、C = 100くらいが正則化パラメータの値として実用的だということが読み取れます。
今回はオーバーフィッティングの概要説明と、その対策としての正則化について、癌データのロジスティック回帰分類を例に説明をしてきました。
新たに利用した正則化パラメータCやtimeモジュールについて、より詳しく知りたい方は下のリンクから是非チェックしてみてください。
▼パラメータCについて
http://aidiary.hatenablog.com/entry/20150908/1441720346
▼timeモジュール
https://docs.python.jp/3/library/time.html
次回はシリーズ第5弾として、ニューラルネットワークを用いた分類問題についてご説明します。
今後もお楽しみに!
【第5回はこちら】
ニューラルネットワークで分類問題を解く|Pythonで機械学習vol.5

