
教師あり学習の第一歩、線形回帰を解いてみる|Pythonで機械学習vol.2
- Python
- 機械学習
notari株式会社


http://nineties.github.io/NLP-seminar/2.html#/3
「分類問題」とは,データをそれぞれカテゴリに分類するもので,機械学習の代表的な使い道の一つです。例えば、Gmailを利用している方だとなじみ深いと思いますが、メールをスパムと非スパムに分類したり、更に非スパムから文中の単語に名詞や動詞などの品詞ラベルを割り振ってくれたりします。分類問題はデータを2種類に分類する2クラス問題(二値分類)と,3種類以上に分類するマルチクラス問題(多値分類)に大きく分けられます。これら分類問題を解く際に行う前処理などデータ加工の工数や、モデルがそもそも解釈可能なのかなど、データの種類によって分類手法を使い分けます。下の記事に分類問題に限らず機械学習の手法が、わかりやすくまとまっていましたので興味のある方はご参照ください。
【Qiita】代表的な機械学習手法一覧
そして、今回はその手法のひとつであるロジスティック回帰を用いて2クラス問題を解いてみます。
ロジスティック回帰は確率を予測したり、2クラスに分類する手法として使われており、予測結果が0から1の間、もしくは0か1を取るように数式やその前提に改良が加えられています。
主な利用用途としてはマーケティング目的で用いられることが多く、例えばDMの反応する顧客の確率を調べる際に、「性別・年齢・購買履歴などを入力値とし、DMに反応する確率を出力値として算出する」といった具合に利用されています。
今回の場合は、癌データを用いて分類問題を解いていき、訓練データ(学習データ)からモデルを生成し、テストデータを分類させるまでを行います。
まずはいつも通りMacの場合はターミナル、Windowsの場合はコマンドプロンプトから任意のディレクトリに移動し、Jupyterを起動します。
$ jupyter notebook
起動したら新規ファイルを作成して編集画面を表示します。
そして、今回利用するライブラリーやモジュールを下のコマンドでインポートします。
なお、前回と同様の処理については説明を省略しますので、よくわからない処理があった場合、ネットで調べるか前回の記事を読み返すようお願いします。
# 分析用
import numpy as np
# プロット用
import matplotlib.pyplot as plt
%matplotlib inline
# 機械学習用
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import ShuffleSplit
# がんデータ
from sklearn.datasets import load_breast_cancer
では、実際にサンプルデータを読み込んでデータ概要を表示してみましょう。
cancer = load_breast_cancer()
print(cancer.DESCR)

次に、変数にデータを格納します。
X = cancer.data
y = cancer.target
最後に、Cross Validationを行うためにShuffleSplitを使って、元データからテストデータをランダムに選択します。
Cross Validation(交差検証)とは
統計学において標本データを分割し、その一部をまず解析して、残る部分でその解析のテストを行い、解析自身の妥当性の検証・確認に当てる手法を指す。(Wikipediaより引用)
https://ja.wikipedia.org/wiki/%E4%BA%A4%E5%B7%AE%E6%A4%9C%E8%A8%BC
ss = ShuffleSplit(n_splits=1,
train_size=0.8,
test_size=0.2,
random_state=0)
train_index, test_index = next(ss.split(X, y))
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
これで事前準備は終了です。
では実際にロジスティック回帰を使ってがんの発症予測を分類してみましょう。
まずは、ロジスティック回帰のインスタンスを用意します。
clf = LogisticRegression()
次にfit()メソッドを呼んでモデルを生成すると共に、学習データの精度を表示します。
clf.fit(X_train, y_train)
clf.score(X_train, y_train)
次にテストデータでの精度を表示してみます。
基本的には学習データでの精度より、テストデータでの精度のほうが劣っているかと思います。
下のようにロジスティック回帰のインスタンスを見てみると、パラメータがいくつか用意されているのがわかります。
興味のある方はネットや本で調べて自由に調整してみてください。
clf

では、テストデータを実際にどのように識別したのか、予測結果を表示してみます。
clf.predict(X_test)
「0」と表示されているものが悪性の癌と判断されたもの、「1」と表示されたものが良性と判断されたものです。
実際の解えと照らし合わせてみると、どれを間違えてしまったのか見ることが出来ます。
wrong = 0
for i,j in zip(clf.predict(X_test), y_test):
if i == j:
print(i,j)
else:
print(i,j, " Wrong!") # 不正解
wrong += 1
また、ロジスティック回帰では識別境界からどれくらい離れているかが重要です。つまり、識別境界から離れているほど、分類があたっている確率が高く、識別境界に近いほど分類があいまいということです。
サンプルデータと識別境界との距離を求めるのに決定関数decision_function()を用います。
X_test_value = clf.decision_function(X_test)
X_test_value
絶対値が大きければ大きいほど、境界から離れているということになります。
この値を小さい方からソートしてプロットしてみると、下のようになります。
plt.plot(np.sort(X_test_value))
plt.plot([0, 120], [0, 0], linestyle='--')
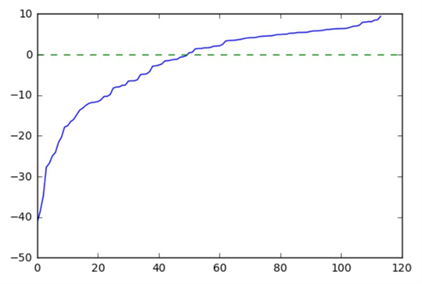
縦軸が識別境界からの距離、横軸がサンプルの番号です。
これをみるとマイナス方向にはたくさん大きくずれているサンプルがあり、プラス方向にはそれほどずれていはいないがたくさんのサンプルがあることがわかります。
また、ロジスティック回帰はシグモイド関数を用いることで、確率を予測することも出来ます。
-∞から∞までの値を入力として受け取って、常に0から1の間の値を返す関数をロジスティック関数(シグモイド関数)と呼びます。
では先程の値をシグモイド関数にいれて、ソートしてプロットしてみます。
def sigmoid(x):
return 1 / (1 + np.exp(-x))
plt.plot(np.sort(sigmoid(X_test_value)))
plt.plot([0, 120], [0.5, 0.5], linestyle='--')
plt.ylim(0,1)
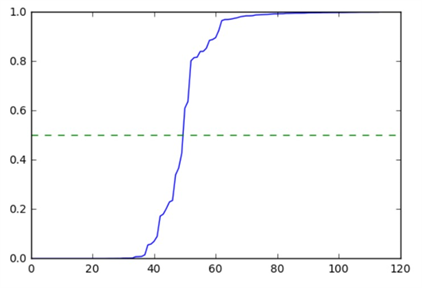
縦軸が0~1の確率、横軸がサンプル番号です。
この図をみると、識別境界付近にあるサンプル番号50付近で確率の変動が大きくみえます。
また、この図を解釈すると、サンプル番号が小さいものほど分類が「1」である確率が低く(分類が「0」である確率が高い)、サンプル番号が大きいほど分類が「1」である確率が高いことがわかります。
今回は分類問題、ロジスティック回帰についての概要説明と、実際に癌データをサンプルにロジスティック回帰を用いて2クラス分類問題を解くところまでを行いました。
今回利用したシグモイド関数について、詳しい数学的背景に興味がある方は下のリンクから是非チェックしてみてください。
次回はシリーズ第4弾として、オーバーフィッティング対策としての正則化をについてご説明します。
今後もお楽しみに!
【第4回はこちら】
オーバーフィッティング対策としての正則化とは|Pythonで機械学習vol.4

