
分類問題を解く方法、ロジスティック回帰を使ってみよう|Pythonで機械学習vol.3
- Python
- 機械学習
notari株式会社


目次
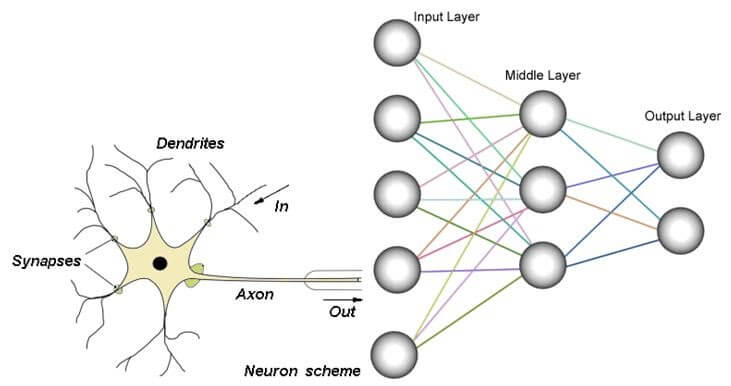
Neural Networks (Computational Intelligence)
非常に端的にいうと脳の特徴を計算機上で表現することを目指した数学モデルのことをニューラルネットワーク(人口神経回路網)といいます。
私たちは日常的に無意識で判断を行っていることが多くあります。
例えば、猫を見かけた時に、どうしてあなたの目の前にいる動物が犬ではなく猫だといえるのでしょうか?それは犬と猫での体格、額の広さや足の形の違いなど、構造的な相違点をあなたが無意識で判別しているからです。
猫の写真をみて(入力)、その判断に至る過程を計算式(モデル)であらわし、最終的に正解と思われる解(この場合は猫)を出力するのがニューラルネットワークです。
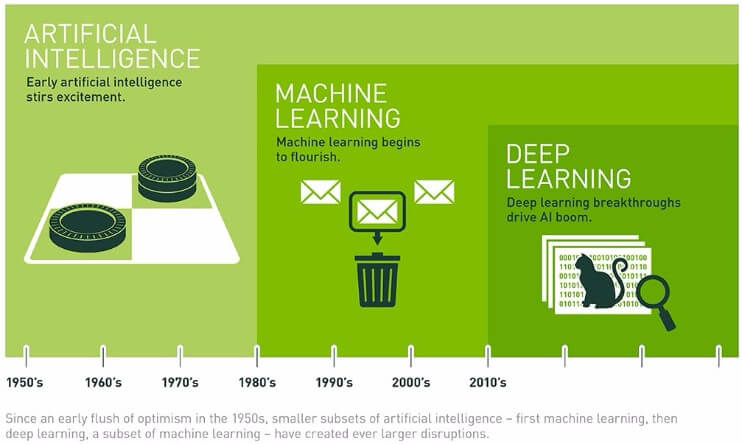
「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか
最近よく耳にするニューラルネットワークですが、この考え方は現在の第3次AIブームよりもずっと昔の第1次AIブーム(1960年代)のころから考えられていたと言われています。
しかし、どうしてここ最近まで一般の人が知る機会が少なかったのでしょうか?
それは、今まで下のような課題があり実用的ではなかったからです。
・学習がうまくいかない(重みの調整が適切に行われない)
・学習データが少ない
・計算資源がない
この問題の解決に大きく関わっているのがディープラーニング(深層学習)の登場、そしてReLU関数を用いることによるニューロンが発火する仕組み(活性化関数)の変更です。
活性化関数とは(引用:Wikipedia)
活性化関数(かっせいかかんすう、英: activation function)もしくは伝達関数(でんたつかんすう、英: transfer function)とは、ニューラルネットワークにおいて、線形変換をした後に適用する非線形関数もしくは恒等関数のこと。
https://ja.wikipedia.org/wiki/%E6%B4%BB%E6%80%A7%E5%8C%96%E9%96%A2%E6%95%B0
ディープラーニングについてはとても参考になる記事がたくさんあるので、ご自身で調べて見てくださいね。
前回までの記事で実際にプログラムしているとおり、モデル(識別器)に学習させるためには学習データ(もしくは訓練データ)を大量にインプットする必要があります。
ビックデータ時代といわれている通り、インターネットやIoTの広がりにより、学習データとして使えるデータも増えてきました。
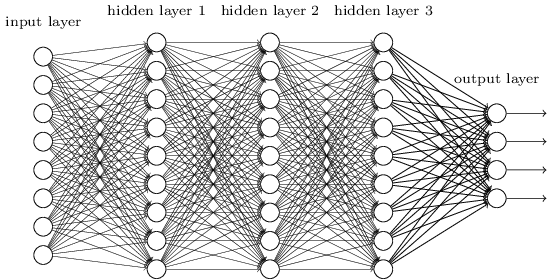
ディープラーニングを用いて計算を行う場合、上の図のように多数の層にわたって計算が行われるため、計算処理機のスペックが問われます。
そこで登場したのがGPGPU(General-purpose computing on graphics processing units)です。横文字でなんだかわかりづらいですがGPGPUを直訳すると「GPUによる汎用計算」となります。
では、そもそもGPUとは何でしょうか。
GPGPU概要(引用:Wikipedia)
GPUは一般的に画像処理を専門とする演算装置であり、多くの場合、CPUと呼ばれる主演算装置の制御の下で用いられる動画信号生成専用の補助演算用ICである。動画像の実時間内での生成は高負荷な演算能力が要求されるが、その多くが定式化された単純な演算の繰り返しであるためハードウェア化に向いており、GPUを設計している数社からは、高速なメモリ・インターフェイス機能と高い画像演算能力を備えたIC製品のシリーズがいくつもリリースされている。
特に1990年代中盤以降は3D描画性能が劇的に向上し、それに伴いベクトル・行列演算を中心としたSIMD演算機の色彩が強くなってきた。2000年代に入ると、表現力の向上を求めて固定機能シェーダーからプログラマブルシェーダーへの移行が進み、演算の自由度・柔軟性(プログラマビリティ)が飛躍的に増した。そこでこれをグラフィックス・レンダリングのみならず、他の数値演算にも利用しようというのがGPGPUのコンセプトである。
簡単にいうと、CGを用いたゲームなど高度な計算処理を求められる場合、PCに搭載されているCPUだけでは処理することができないため、代わりに処理してもらうものとして利用されていました。
しかし、CGを実現するための大量の行列演算は、ニューラルネットワークの計算にも応用できるため、本来の目的である画像処理以外でも使われるようになったということです。これら技術の進歩や数学的なブレークスルーなどにより、ニューラルネットワークが見直されてきました。
では実際にニューラルネットワークを用いて分類問題を解くプログラムを書いていきましょう。
今回はTensorFlow(テンソルフロー)という、Googleが提供する機械学習/ディープラーニング/多層ニューラルネットワークライブラリを利用します。TensorFlowはデフォルトではanacondaのパッケージに含まれていなため、インストールしてくる必要があります。
インストール方法としては、anacondaディレクトリ配下のenvsフォルダに仮想環境がはいっているので、インストールしたい環境にpipコマンドでTensorFlowをインストールします。
私の場合)
/Users/ユーザー名/anaconda/envs/ にて、
source activate
pip install tensorflow
でインストールできました。
確認方法は、Anaconda Navigatorを起動してEnvironmentsから「tensorflow」で検索することで確認できます。
▼参考記事(解決方法:pip で別途インストールする)
Anaconda環境に独自にモジュールを追加する
TensorFlowが無事インストールできたら、いつも通りMacの場合はターミナル、Windowsの場合はコマンドプロンプトから任意のディレクトリに移動し、Jupyterを起動します。
起動したら新規ファイルを作成して編集画面を表示します。そして初めに今回利用するTensorFlowライブラリを下のコマンドでインポートします。
import tensorflow as tf
次に、サンプルデータを読み込み変数にデータを格納します。
今回はTensorFlowのチュートリアルで用意されてある手書き文字をサンプルデータとして扱います。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
※上のコマンドを実行すると、Pythonファイルと同階層にMNIST_dataというフォルダが作成され、そこに手書き文字データが格納されていることが確認できます。
次に訓練画像を入れる変数xを用意し、訓練画像を1行784列のベクトルに並び替えて格納します。
x = tf.placeholder(tf.float32, [None, 784])
さらに重み(Weight)とバイアス(Bias)をそれぞれ行列として変数に格納します。
※初期値として0を入れておく(zeros = ゼロ行列)
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
次に活性化関数としてソフトマックス回帰を実行します。
▼ソフトマックス回帰について
機械学習のフレームワークTensorflowを試す 8 – ソフトマックス回帰
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_には正解データのラベルを格納し、交差エントロピー(?∑y′log?(y))というコスト関数を用いて計算します。
▼交差エントロピーについて
第3章 ニューラルネットワークの学習の改善
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
最後に、勾配硬化法を用いて交差エントロピーが最小となるようにyを最適化し、セッションの開始、runにより実行を開始します。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
では実際にnext_batch(100)で100つのランダムな訓練セット(画像と対応するラベル)を選択し、1000回ほど訓練(train_step)を実行してみましょう。
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
実行結果をもとに答え合わせをしていきます。計算された画像がどの数字であるかの予測yと正解ラベルy_を比較し、同じ値であればTrueが返されます。
また次の行で、correct_predictionのbooleanをfloatにキャストし、平均値を計算することで精度を算出します。
※Trueならば1、Falseならば0に変換される
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
実際に精度の実行と表示をしてみると約92%の正答率がでてくるかと思います。
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
今回は下のビギナー向けのチュートリアルに沿って実行してきましたが、エキスパート向けのチュートリアルで実行すると約99%までの正答率までいくようです。
▼MNIST For ML Beginners
https://www.tensorflow.org/get_started/mnist/beginners
▼Deep MNIST for Experts
https://www.tensorflow.org/get_started/mnist/pros
これは今まで使っていたscikit-learnと比べてみると、より精度が高いということがわかります。

▼参考記事
TensorFlowとscikit-learnを比べてみた ~文字認識編
今回はニューラルネットワークの概要から、TensorFlowというディープラーニングのライブラリを用いて、実際にチュートリアルに沿ってプログラムをしました。
TensorFlowとは何なのかより詳しく知りたい方は下のリンクから是非チェックしてみてくださいね。
▼TensorFlowの参考記事
オープンソースのAI・人工知能/TensorFlowとは
次回はシリーズ第6弾として、教師なし学習の第一歩クラスタリングについてご説明します。
今後もお楽しみに!
【第6回はこちら】
教師なし学習の第一歩(クラスタリング)|Pythonで機械学習vol.6

